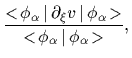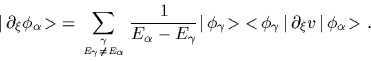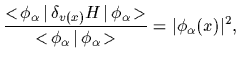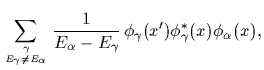A maximum likelihood approach selects
the potential ![]() with
maximal likelihood
with
maximal likelihood
![]() under the training data.
Beginning with a discussion of the parametric approach
we consider a potential
under the training data.
Beginning with a discussion of the parametric approach
we consider a potential
![]() parameterized by a parameter vector
parameterized by a parameter vector ![]() with components
with components ![]() .
To find the parameter vector which maximizes the
training likelihood
we have to solve the stationarity equation
.
To find the parameter vector which maximizes the
training likelihood
we have to solve the stationarity equation
| (23) |
| (27) |
While a parametric approach restricts the space of possible potentials ![]() ,
a nonparametric approach
treats each function value
,
a nonparametric approach
treats each function value ![]() itself
as individual degree of freedom,
not restricting the space of potentials.
The corresponding nonparametric stationarity equation is obtained
analogous to
the parametric stationarity equation (21)
replacing
partial derivatives
itself
as individual degree of freedom,
not restricting the space of potentials.
The corresponding nonparametric stationarity equation is obtained
analogous to
the parametric stationarity equation (21)
replacing
partial derivatives ![]() with the functional derivative operator
with the functional derivative operator
![]() =
=
![]() with components
with components
![]() =
=
![]() [59].
Because the functional derivative of
[59].
Because the functional derivative of ![]() is simply
is simply
| (31) | |||
The large flexibility of the nonparametric approach
allows an optimal adaption of ![]() to the available training data.
However, as it is well known in the context of learning
it is the same flexibility
which makes a satisfactory generalization
to non-training data (e.g., in the future)
impossible,
leading, for example, to `pathological',
to the available training data.
However, as it is well known in the context of learning
it is the same flexibility
which makes a satisfactory generalization
to non-training data (e.g., in the future)
impossible,
leading, for example, to `pathological',
![]() -functional like solutions.
Nonparametric approaches
require therefore additional restrictions in form
of a priori information.
In the next section we will include
a priori information in form of stochastic processes,
similarly to Bayesian statistics with Gaussian processes
[16, 37, 44, 48, 60-63] or to classical regularization theory
[2,4,16].
In particular, a priori information will be implemented
explicitly, by which we mean
it will be expressed directly in terms of the function values
-functional like solutions.
Nonparametric approaches
require therefore additional restrictions in form
of a priori information.
In the next section we will include
a priori information in form of stochastic processes,
similarly to Bayesian statistics with Gaussian processes
[16, 37, 44, 48, 60-63] or to classical regularization theory
[2,4,16].
In particular, a priori information will be implemented
explicitly, by which we mean
it will be expressed directly in terms of the function values ![]() itself.
This is a great advantage over parametric methods
where a priori information
is implicit in the chosen parameterization,
thus typically difficult or impossible to analyze
and not easily adapted to the situation under study.
Indeed, because it is only a priori knowledge
which relates training to non-training data,
its explicit control is essential
for any successful learning.
itself.
This is a great advantage over parametric methods
where a priori information
is implicit in the chosen parameterization,
thus typically difficult or impossible to analyze
and not easily adapted to the situation under study.
Indeed, because it is only a priori knowledge
which relates training to non-training data,
its explicit control is essential
for any successful learning.