Technically, one is interested in function approximation in finding
a function or hypothesis ![]() which minimizes
a given error/energy functional
which minimizes
a given error/energy functional ![]() .
Using a Bayesian interpretation2
we understand the error functional
up to a constant as proportional to the posterior log-probability
for the function
.
Using a Bayesian interpretation2
we understand the error functional
up to a constant as proportional to the posterior log-probability
for the function ![]() given training data
given training data ![]() and prior informations
and prior informations ![]() , i.e.
, i.e.
| (1) |
The error functional usually depends
as well on a finite number of training data ![]() as also on additional prior informations
as also on additional prior informations ![]() .
Special cases of function approximation
include density estimation where
.
Special cases of function approximation
include density estimation where ![]() has to fulfill
an additional normalization condition
or classification or pattern recognition
where the function
has to fulfill
an additional normalization condition
or classification or pattern recognition
where the function ![]() takes only discrete values
representing the possible classes or patterns of
takes only discrete values
representing the possible classes or patterns of ![]() .
.
Let us consider as example an error functional with
mean square data terms and a typical smoothness constraint
for ![]() -dimensional
-dimensional ![]()
For the smoothness constraint in (2) we find
the quite similar form
These examples motivate the following general definitions.
Let ![]() denote a Hilbert space3of hypothesis functions
denote a Hilbert space3of hypothesis functions ![]() of
of ![]() -dimensional
-dimensional ![]() .
.
Definition 1 ( (prior) concept ![]() with
(prior) template
with
(prior) template ![]() and template distance
and template distance ![]() ):
A prior concept is a pair
):
A prior concept is a pair ![]() with
with ![]() a function in
a function in ![]() and
and
![]() a (``distance'') functional with
a (``distance'') functional with ![]() .
Note that this allows
.
Note that this allows ![]() for
for ![]() .
We write
.
We write ![]() .
The function
.
The function ![]() will be called a (prior) template.
will be called a (prior) template.
Template functions will be used to represent function prototypes.
Notice that templates include standard training data
which is the reason for the brackets around the word ``prior''.
We are especially interested in distances quadratic in ![]() ,
for which the functional derivative with respect to
,
for which the functional derivative with respect to ![]() is linear.
Such distances can be defined by positive semi-definite operators
is linear.
Such distances can be defined by positive semi-definite operators ![]() .
Such operators
have a decomposition
.
Such operators
have a decomposition ![]() with
with ![]() invertible if
invertible if ![]() positive definite.
More precisely,
positive definite.
More precisely,
![]() =
= ![]() =
= ![]() defines a semi-norm on
defines a semi-norm on ![]() with
with ![]() if
if
![]() is in the zero space of
is in the zero space of ![]() , i.e. if
, i.e. if ![]() .
Typical
.
Typical ![]() are projectors into the space of training data
like in
are projectors into the space of training data
like in ![]() and generators of infinitesimal transformations
of continuous Lie groups, like the gradient
and generators of infinitesimal transformations
of continuous Lie groups, like the gradient ![]() for translations in (4)
with
for translations in (4)
with
![]() under appropriate boundary conditions.
Thus, we define:
under appropriate boundary conditions.
Thus, we define:
Definition 2 (quadratic (prior) concept ![]() with template distance operator
with template distance operator ![]() ):
A quadratic (prior) concept is a pair
):
A quadratic (prior) concept is a pair ![]() with
with ![]() a function in
a function in ![]() and a symmetric and positive semi-definite operator
and a symmetric and positive semi-definite operator ![]() which will be called a template distance operator.
which will be called a template distance operator.
![]() defines the square template distance:
defines the square template distance:
| (6) |
Thus, a quadratic concept defines a
![]() -dimensional Gaussian process
with
-dimensional Gaussian process
with
![]() and covariance operator
and covariance operator ![]() .
Its matrix elements are sometimes also
called Green´s function, propagator or two-point
correlation function.
The Laplacian (4), for example,
corresponds to the Wiener measure
known from Brownian motion or diffusion
and is also used as kinetic energy
for Euclidean scalar fields in physics
(see for example [2].
The zero modes of
.
Its matrix elements are sometimes also
called Green´s function, propagator or two-point
correlation function.
The Laplacian (4), for example,
corresponds to the Wiener measure
known from Brownian motion or diffusion
and is also used as kinetic energy
for Euclidean scalar fields in physics
(see for example [2].
The zero modes of ![]() represent the
projections of
represent the
projections of ![]() which do not contribute to
which do not contribute to ![]() .
The projector
.
The projector ![]() in the mean square error term (3),
for example,
measures the distance only at (training data) point
in the mean square error term (3),
for example,
measures the distance only at (training data) point ![]() .
Also continuous template functions
may be restricted to subspaces, e.g. parts of an image
or a specific resolution.
.
Also continuous template functions
may be restricted to subspaces, e.g. parts of an image
or a specific resolution.
Definition 3 (template space ![]() and template projectors
and template projectors ![]() ):
The maximal subspace on which the positive semi-definite
):
The maximal subspace on which the positive semi-definite
![]() is positive definite
will be called the template space
is positive definite
will be called the template space ![]() of
of ![]() .
The corresponding hermitian projector
.
The corresponding hermitian projector ![]() in this subspace
in this subspace ![]() , i.e.
, i.e.
![]() ,
,
![]() ,
and
,
and ![]() will be called template projector.
will be called template projector.
Hence ![]() commutes with the template projector
commutes with the template projector
![]() .
Maximality of
.
Maximality of ![]() means that
means that
![]() is the projector in the zero space of
is the projector in the zero space of ![]() i.e.
i.e.
![]() .
Our aim is to built an error functional
.
Our aim is to built an error functional
![]() depending on
depending on ![]() over square distances
over square distances ![]() .
.
![\begin{displaymath}
E[h] = \frac{1}{2} \sum_i^n (y_i-h(x_i))^2
+\frac{\lambda}{...
...um_{l=1}^d \left( \frac{\partial h(x)}{\partial x_l}\right)^2.
\end{displaymath}](img20.png)
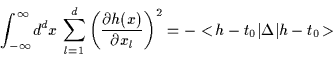
![\begin{displaymath}
E[h] = \frac{1}{2} \sum_i^n <\! h - t_i \vert P_i\vert h - t_i\!>
- \frac{\lambda}{2} <\! h - t_0 \vert\Delta \vert h-t_0\!>.
\end{displaymath}](img30.png)