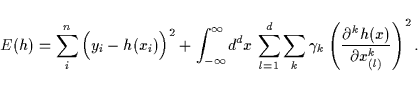As a first step empirical dependency control requires an
explicit and readable formulation of prior knowledge.
By explicit formulation we mean in the following
the expression of prior knowledge
directly in terms of the functions values ![]() ,
like it is done in regularization theory or for stochastic processes.
In an implicit implementation of dependencies, on the other hand,
single function values
,
like it is done in regularization theory or for stochastic processes.
In an implicit implementation of dependencies, on the other hand,
single function values ![]() are not parameterized independently.
Examples include neural networks, linear, additive or tensor models.
Also the realization of learning algorithms can induce dependencies,
e.g., due to restricted initial conditions and stopping rules.
are not parameterized independently.
Examples include neural networks, linear, additive or tensor models.
Also the realization of learning algorithms can induce dependencies,
e.g., due to restricted initial conditions and stopping rules.
In the regularization framework an approximation ![]() is chosen to minimize a regularization or error
functional
is chosen to minimize a regularization or error
functional ![]() . Prior knowledge can be represented
by a regularization term added to the training error.
A typical example of a smoothness related
regularization functional for
. Prior knowledge can be represented
by a regularization term added to the training error.
A typical example of a smoothness related
regularization functional for ![]() -dimensional
-dimensional ![]() =
=
![]() is
is
![\begin{displaymath}
(y_i-h(x_i))^2
= \int_{-\infty}^\infty \!d^dx \, \delta (x-...
...ule[\tiefe]{0cm}{\hoehe}
\right\vert h-t_i\right\rangle $}
,
\end{displaymath}](img34.png)
![\begin{displaymath}
\int_{-\infty}^\infty \!d^dx\,
\sum_{l=1}^d \left( \frac{\p...
...ule[\tiefe]{0cm}{\hoehe}
\right\vert h-t_0\right\rangle $}
,
\end{displaymath}](img38.png)
Definition. (Quadratic concept.)
A quadratic concept is a pair ![]() consisting of a template function
consisting of a template function
![]() and a real symmetric, positive semi-definite operator on
and a real symmetric, positive semi-definite operator on ![]() ,
the concept operator
,
the concept operator ![]() .
The operator
.
The operator ![]() defines a concept distance
defines a concept distance
![]() on subspaces where it is positive definite.
The maximal subspace in which the positive semi-definite
on subspaces where it is positive definite.
The maximal subspace in which the positive semi-definite
![]() is positive definite
is the concept space
is positive definite
is the concept space ![]() of
of ![]() .
The corresponding hermitian projector
.
The corresponding hermitian projector ![]() in this subspace
in this subspace ![]() is the concept projector.
is the concept projector.
Remark 1 (Approximate symmetries):
Typical concept operators ![]() are related to symmetries.
Let for example
are related to symmetries.
Let for example
![]() with
with
![]() a permutation within
a permutation within ![]() , i.e., one-to-one.
Then
, i.e., one-to-one.
Then ![]() =
= ![]() , with identity
, with identity ![]() and
and ![]() denoting the transpose,
defines a symmetry concept
denoting the transpose,
defines a symmetry concept
![]() .
Similarly, assume
.
Similarly, assume
![]() to be a continuous symmetry (Lie) group, parameterized
by
to be a continuous symmetry (Lie) group, parameterized
by ![]() and with infinitesimal generators
and with infinitesimal generators ![]() .
Then
an infinitesimal symmetry concept for
.
Then
an infinitesimal symmetry concept for
![]() is defined by
is defined by
![]() .
For infinitesimal translations (smoothness)
.
For infinitesimal translations (smoothness)
![]() .
.
Remark 2 (Gaussian processes):
A quadratic concept defines a Gaussian process
according to
![]() with covariance operator
with covariance operator ![]() .
We remark however,
that while Gaussian processes can also be defined for continuous
.
We remark however,
that while Gaussian processes can also be defined for continuous
![]() [2,7]
we do not discuss continuum limits for the non-Gaussian extensions below.
In these cases we refer to a lattice approximation.
[2,7]
we do not discuss continuum limits for the non-Gaussian extensions below.
In these cases we refer to a lattice approximation.
Remark 3 (Support vector machine):
Expanding
![]() in a basis of eigenfunctions of
in a basis of eigenfunctions of
![]() one obtains
one obtains
![]() =
=
![]() .
Replacing the mean-square training error
by Vapnik's
.
Replacing the mean-square training error
by Vapnik's ![]() -insensitive error
yields a support vector machine with kernel
-insensitive error
yields a support vector machine with kernel ![]() [6].
In general, flat regions of
[6].
In general, flat regions of ![]() as they appear in
the
as they appear in
the ![]() -insensitive error and other robust error
functions have the technical advantage
that they do not contribute to the gradient and can be ignored
within a saddle point approximation.
-insensitive error and other robust error
functions have the technical advantage
that they do not contribute to the gradient and can be ignored
within a saddle point approximation.
Remark 4 (Templates):
Templates ![]() can be constructed directly
by experts. They also can represent a structural hypothesis
realized by a parameterized
learning system like a neural network.
Templates can be used for transfer
by choosing them as the output of a learning system trained
for a similar situation.
For finite spaces templates can in principle be estimated by sampling.
can be constructed directly
by experts. They also can represent a structural hypothesis
realized by a parameterized
learning system like a neural network.
Templates can be used for transfer
by choosing them as the output of a learning system trained
for a similar situation.
For finite spaces templates can in principle be estimated by sampling.
Remark 5 (Covariances):
Covariances ![]() can be given directly by experts.
They do not necessarily have to be local
but can include non-local correlations.
As already remarked they are often constructed from
symmetry considerations.
For finite spaces covariances can in principle also be
estimated by sampling.
can be given directly by experts.
They do not necessarily have to be local
but can include non-local correlations.
As already remarked they are often constructed from
symmetry considerations.
For finite spaces covariances can in principle also be
estimated by sampling.